[미래를 담아낸 뼈대 7/7] 의존성의 방향을 따라

레포의 경계를 넘어서
지난 여섯 편을 통해, 경계를 깎아 모듈을 만들고 그 경계가 인과 사슬로 이어지는 과정을 따라왔습니다. 하지만 여기까지의 이야기는 대부분 하나의 레포, 혹은 하나의 배포 단위 안에서 일어나는 일이었습니다.
flex 백엔드는 50개 이상의 레포, 3500개 이상의 모듈로 구성된 생태계입니다. flex-gradle-plugins가 모든 레포의 빌드 규칙을 정의하고, flex-commons가 공통 라이브러리를 제공하며, flex-v2-backend-commons가 Spring Boot 기반의 자동 설정을 관리합니다. 이 레포들은 서로 의존하고, 변경은 의존성의 방향을 따라 전파되어야 합니다.
마지막 화에서는, 1화부터 쌓아온 구조적 일관성이 이 생태계 전체를 관통할 때 어떤 일이 가능해지는지를 이야기합니다.
버전업의 현실 — 미루면 쌓이고, 쌓이면 터진다
Spring Boot 버전을 올린다고 합시다. 단순한 작업처럼 들리지만, flex 규모에서는 이렇게 흘러갑니다.
먼저 파이오니어가 한두 레포에서 버전업을 시도합니다. MySQL 커넥터가 커넥션 릭을 일으키는 걸 발견하고, 버전을 조정합니다. 이 경험을 문서화하고 슬랙에 공유합니다. 다른 레포 담당자들이 각자 작업을 시작합니다. 중간에 버전이 다시 바뀌면, 이미 작업한 사람에게 "죄송합니다, 다시 수정해주세요"라고 연락합니다. 누가 어떤 버전으로 작업했는지 추적하기 어렵고, 진행 상황 싱크에 별도의 커뮤니케이션 비용이 듭니다.
한 번의 버전업에 수 주가 소요됩니다. 그 과정에서 "지금 당장 문제없으니" 미루는 습관이 생깁니다. 미루면 기술 부채가 쌓이고, 나중에 한꺼번에 올리려면 더 힘들어지는 악순환. 보안 취약점이 발견되었을 때 전 레포에 걸쳐 패치를 빠르게 적용할 수 없다는 건, 조직 수준의 리스크입니다.
Evergreen — 의존 그래프를 따라 전파하는 자동화
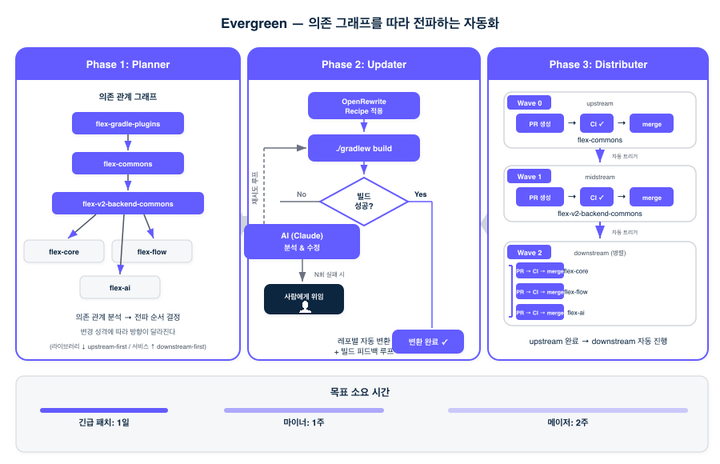
flex는 이 문제를 Evergreen이라는 내부 플랫폼으로 풀고 있습니다. 핵심은 "의존 관계 그래프를 분석하고, 그 방향을 따라 순서대로 마이그레이션을 전파하는 것"입니다.
Planner — 의존 관계를 읽는다
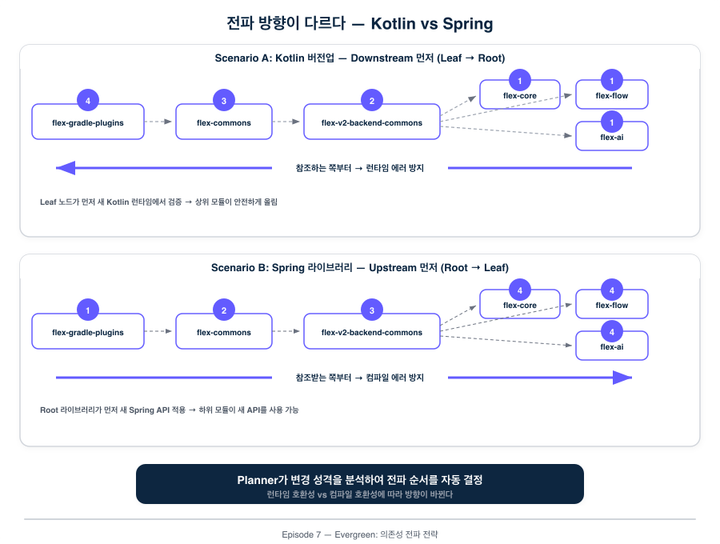
Planner는 레포 간 의존 관계를 파악하고, 변경이 전파되어야 하는 순서를 결정합니다. 이건 단순한 목록이 아닙니다. Kotlin 버전을 올릴 때는 참조하는 쪽(downstream)부터 올려야 런타임 에러를 방지할 수 있고, Spring 라이브러리를 올릴 때는 참조받는 쪽(upstream)부터 올려야 컴파일 에러를 방지할 수 있습니다. 변경의 성격에 따라 전파 방향이 달라지고, Planner가 이 순서를 자동으로 결정합니다.
이게 가능한 이유는, 1화에서 이야기한 version-management-plugin이 모든 레포에서 의존성을 같은 방식으로 선언하게 강제하기 때문입니다. 의존 관계가 일관된 형식으로 표현되어 있으니, 그래프를 파싱하고 순서를 도출하는 것이 자동화 가능해집니다.
Updater — 코드를 변환한다
순서가 정해지면 Updater가 레포별로 실제 코드 변환을 수행합니다. OpenRewrite recipe로 정적 변환을 먼저 적용하고, 빌드를 돌려봅니다. recipe만으로 해결되지 않는 경우 — 예를 들어 API 시그니처가 바뀌어서 호출 코드를 수정해야 하는 경우 — AI(Claude)가 빌드 에러를 분석하고 수정을 시도합니다. 수정 후 다시 빌드, 다시 테스트. 이 루프를 자동으로 반복합니다.
여기서 6화의 이야기가 연결됩니다. AI가 코드를 수정할 때, 1화의 빌드 가드레일이 작동합니다. 잘못된 수정은 빌드가 잡아내고, AI는 피드백을 받아 방향을 수정합니다. N번 시도해도 실패하면 그때 사람에게 넘깁니다. 사람은 전체 과정이 아니라, 자동화가 풀지 못한 예외만 처리하면 됩니다.
이것도 1화의 구조적 일관성 덕분입니다. 모든 레포가 같은 Convention Plugin, 같은 build-recipe 타입 시스템, 같은 version-management 체계를 따르기 때문에, recipe 하나가 모든 레포에 동일하게 작동합니다. 레포마다 빌드 구조가 달랐다면, 레포당 별도 recipe가 필요했을 것이고, 그건 자동화가 아니라 또 다른 수동 작업입니다.
Distributer — PR을 전파한다
변환이 완료되면 Distributer가 PR을 생성하고, CI 상태를 추적하고, 머지 여부를 관리합니다. 의존 그래프의 순서에 따라, upstream 레포의 PR이 머지되고 새 버전이 퍼블리시되면, 그 다음 순서의 downstream 레포에 PR이 자동으로 올라갑니다. 사람은 리뷰와 예외 처리에만 개입합니다.
목표는 명확합니다. 긴급 보안 패치는 하루 안에, 마이너 버전업은 일주일 안에, 메이저 버전업은 2주 안에. 버전업을 미루지 않고 꾸준히 할 수 있게 만드는 것.
일관성의 최종 형태
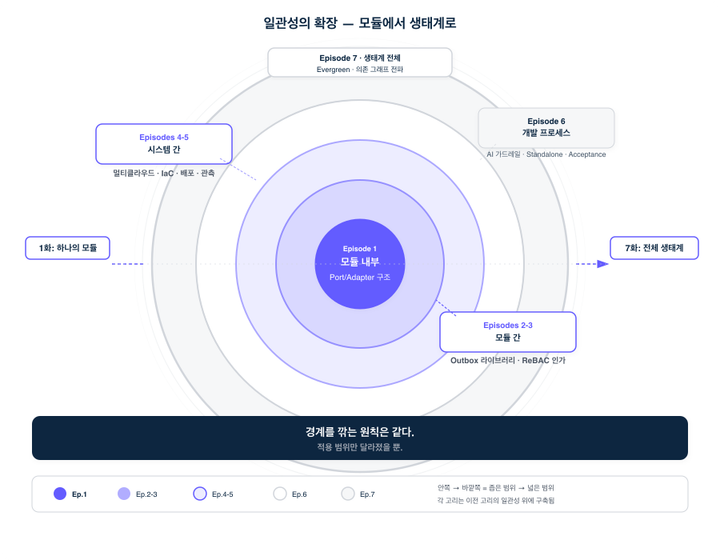
시리즈를 처음부터 돌아보면, 하나의 원칙이 점점 더 넓은 범위로 확장되는 과정이 보입니다.
1화에서 그 원칙이 시작되었습니다. Gradle Convention Plugin이 모듈의 의존성 방향을 강제하고, flex-skeleton이 구조를 통일했습니다. 이 일관성이 2화에서 Outbox 라이브러리를 가능하게 했고, 3화에서 전사적 인가 체계의 기반이 되었습니다. 4화에서는 멀티클라우드와 AI와 Observability로, 5화에서는 IaC와 배포와 개발 도구로, 6화에서는 AI 에이전트와의 협업으로 확장되었습니다.
Evergreen은 이 인과 사슬의 마지막 고리입니다. 하나의 레포 안에서 작동하던 구조적 일관성이, 레포의 경계를 넘어 생태계 전체를 관통하는 자동화 파이프라인이 된 것. 의존성의 방향을 따라 변경이 전파되고, 그 전파의 각 단계에서 빌드가 검증하고, AI가 보조하고, 사람은 판단에만 집중합니다.
1화에서 깎아낸 경계가, 7화에서 생태계 전체의 자동화로 돌아옵니다.
다음 문제는 이미 도착해 있다
이 구조가 탑다운 전략에서 나온 게 아니라는 점이 중요합니다. flex의 엔지니어들은 스쿼드 안에서 도메인 제품을 만들면서, 동시에 "이 결정이 옆 팀에도 통하는가"를 물었습니다. 그 질문이 Convention Plugin이 되었고, Outbox 라이브러리가 되었고, ReBAC 모델이 되었고, 표준 기반 Observability가 되었고, Kotlin IaC가 되었고, Evergreen이 되었습니다.
대용량 트래픽을 자랑하는 팀은 많습니다. 복잡한 아키텍처를 그린 팀도 많습니다. 하지만 경계를 깎아서 모듈을 만들고, 그 모듈 사이의 인과를 설계하고, 그 인과가 다음 문제의 출발점이 되는 경험을 반복해본 팀은 많지 않습니다.
구조가 준비되어 있다는 건, 다음 문제가 와도 처음부터 시작하지 않는다는 뜻입니다.
구조는 그것을 발전시키는 사람이 있을 때만 살아 있습니다. 경계를 깎는 일은 끝나지 않고, 플렉스팀은 이 인과 사슬의 다음 고리를 만들 동료를 찾고 있습니다.
🚀플렉스팀 채용페이지 바로가기
☕flex Private Talk 신청하기