[코드가 환경을 모르는 구조 7/7] Variant와 스냅샷 캐시, 그리고 다섯 축의 총합

variant가 모듈 경계를 그리는 방식
현실의 멀티모듈 프로젝트는 "한 종류의 DB로 한 벌의 스키마"만 쓰지 않습니다. 6화에서 하나의 컨테이너를 공유하며 모듈마다 논리 스키마를 분리하는 설계를 보았지만, 여기서 한 발 더 나아가야 합니다.
flex의 여러 도메인은 CQRS와 CDC 위에 섭니다. 쓰기 경로는 MySQL writer에 반영되고, 그 변경은 Kafka를 타고 읽기 전용 MySQL reader 또는 Elasticsearch로 흘러갑니다. writer와 reader는 같은 MySQL 엔진이라도 스키마 모양이 다르고, changelog가 다르며, 테스트 시나리오가 요구하는 초기 상태도 다릅니다. 어떤 모듈은 MySQL 8.0에서, 어떤 모듈은 8.4에서 테스트해야 합니다(업그레이드 중이라면 둘 다).
flex의 testcontainers 플러그인은 이 요구를 "variant"라는 개념으로 풉니다. variant는 "어떤 이미지, 어떤 초기화 스크립트, 어떤 설정 조합을 가진 컨테이너 계열인가"를 식별하는 값 객체입니다. 같은 variant에 속한 모듈은 하나의 컨테이너를 공유하고, 다른 variant에 속한 모듈은 별도의 컨테이너를 씁니다.
data class JdbcDatabaseVariantConfig(
val baseImage: String,
val initScripts: List<String>,
val containerEnv: Map<String, String>,
val startupTimeout: Duration,
val reuseEnabled: Boolean,
val variantKey: String,
)이 데이터 클래스 하나가 variant의 정체성을 규정합니다. 필드 조합이 같으면 같은 variant, 하나라도 다르면 별도의 BuildService 인스턴스가 생성됩니다. 결과적으로 빌드 전체에서 살아 있는 컨테이너의 수는 "실제로 필요한 variant의 수"만큼입니다. 많지도 적지도 않습니다.
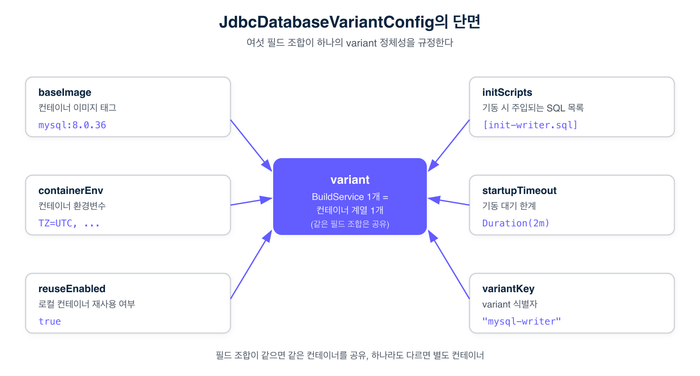
"무엇이 다르면 컨테이너를 새로 띄워야 하는가." variant는 이 판단을 플러그인 내부 로직이 아니라 데이터 필드로 드러냅니다. 이미지 태그가 달라졌는가, 초기화 스크립트가 바뀌었는가, 환경변수가 다른가. 경계를 분명히 그으면 교체와 공유의 단위가 자연스럽게 정해진다—본 시리즈가 반복해 온 원칙이 여기서도 똑같이 작동합니다.
writer와 reader를 테스트에서 분리한다
variant 개념이 빛을 발하는 곳은 CQRS/CDC 테스트입니다. writer 모듈은 "커맨드가 들어왔을 때 writer DB에 어떤 변경이 일어나는가"를 검증하고, reader 모듈은 "writer의 변경이 CDC를 거쳐 reader DB에 도착했을 때 조회 결과가 기대한 모양인가"를 검증합니다. 두 모듈은 서로 다른 시점의 데이터 상태를 요구하고, 서로 다른 Liquibase changelog를 가집니다.
이때 "writer variant"와 "reader variant"를 분리해 선언하면, writer 테스트는 writer 컨테이너의 한 논리 스키마를 쓰고, reader 테스트는 reader 컨테이너의 한 논리 스키마를 씁니다. 같은 MySQL 이미지라도 초기화 스크립트가 다르면 variant가 갈라지고, 두 컨테이너가 독립적으로 준비됩니다. 각 variant 안에서는 여전히 컨테이너 공유가 유지되어, writer 모듈 열 개가 하나의 writer 컨테이너를, reader 모듈 다섯 개가 하나의 reader 컨테이너를 나눠 씁니다.
이 구조의 의미는 테스트 인프라가 프로덕션의 모습을 그대로 닮는다는 점에 있습니다. 프로덕션에서 writer와 reader가 분리되어 있다면 테스트도 그 분리를 따르고, 프로덕션에서 여러 서비스가 하나의 DB 인스턴스를 스키마로 나눠 쓴다면 테스트에서도 같은 분리를 재현합니다. 본편 1화의 "단일 JVM + 논리적 스키마 격리"가 테스트 인프라로 그대로 옮겨 간 모양입니다. "이 모듈은 어느 variant에 속하는가"를 플러그인 DSL로 선언하는 순간, 컨테이너 공유 경계와 데이터 격리 경계가 한 번에 정해집니다.
Liquibase changelog와 스냅샷 캐시
그런데 모듈이 수십 개라면 수십 개의 논리 스키마를 매번 Liquibase로 초기화해야 합니다. changelog가 길어질수록 이 초기화가 새로운 병목입니다. "컨테이너 기동은 한 번이지만 Liquibase는 매 모듈마다"라면, 개선 폭이 절반으로 깎입니다.
flex의 플러그인은 이 문제를 스냅샷 캐시로 풉니다. 한 variant + 한 changelog 세트의 조합이 결정되면, 그 조합을 키로 해시를 만듭니다. 이 해시에 해당하는 "이미 초기화된 DB의 스냅샷"이 로컬 캐시에 있으면, 다음 빌드에서는 Liquibase를 다시 돌리지 않고 스냅샷에서 DB 상태를 복원합니다.

캐시 키 전략은 생각보다 까다롭습니다. 해시에 반영해야 하는 입력은 크게 네 갈래입니다.
첫째, Liquibase changelog 파일들의 내용 해시. 모듈의 DB 초기 상태를 결정하는 모든 .yaml/.xml changelog와 include로 끌어오는 하위 파일까지 재귀적으로 포함합니다.
둘째, DB 이미지 버전 자체. MySQL 8.0.33과 8.0.36은 기본 character set, sql_mode 기본값, 인덱스 내부 표현에서 미세한 차이를 낼 수 있어, 이미지 태그가 바뀌면 스냅샷도 함께 버려야 합니다.
셋째, 컨테이너가 시작될 때 주입되는 schemaInit SQL(또는 initScripts)의 내용 해시. 여기에는 CREATE DATABASE 외에도 컬레이션, 유저 권한, 타임존 설정처럼 "스키마 생성 이전에 결정되는" 상태가 담겨, 한 줄만 바뀌어도 결과 DB의 초기 상태가 달라집니다.
넷째, 컨테이너 env와 variant 정체성의 나머지 필드들(containerEnv, startupTimeout, variantKey). variant를 갈라놓는 모든 입력이 키에 들어가야 "changelog는 안 바꿨는데 이미지 태그를 올렸더니 구 스냅샷이 복원되어 테스트가 틀렸다" 같은 혼란을 막습니다.
실제로 초기 구현에서는 캐시 키에 changelog 내용만 반영하고 이미지 태그를 빼먹었다가, MySQL 마이너 버전을 올린 날 팀 절반이 영문 모를 테스트 실패를 한 시간 정도 추적한 적이 있습니다. 그 뒤로 "variant 정체성을 결정하는 모든 필드는 캐시 키에 들어간다"는 규칙을 주석 한 줄로 박제해 두었습니다.
이 캐시는 컨테이너 이미지 레이어와 비슷한 논리로 작동합니다. 네 입력 중 하나라도 바뀌면 해시가 달라지고 캐시가 무효화되어 Liquibase가 다시 실행됩니다. 바뀌지 않았다면 스냅샷에서 즉시 복원됩니다. changelog를 건드릴 때마다 캐시가 새로 만들어지지만, 그 사이 수많은 빌드에서는 스��냅샷 복원만 일어납니다.
본편 5화가 언급한 "통합 테스트 시간 80% 감소"는 컨테이너 공유와 스냅샷 캐시가 함께 누적된 결과입니다. 컨테이너 공유가 Docker 기동 오버헤드를 걷어 내고, 스냅샷 캐시가 스키마 초기화 오버헤드를 걷어 냅니다. 두 축이 함께 작동하지 않으면 어느 한쪽도 완결되지 않습니다.
수치가 말하는 것
"10분이 2분으로 줄었다"—결과를 숫자로만 말하면 평범하게 들리지만, 이 8분은 두 층의 의미를 품습니다.
첫 번째 층은 개발자 개인의 일입니다. 하루에 CI를 열 번 기다린다면 하루 80분을 되찾습니다. 더 중요한 것은 피드백 루프의 질적 변화입니다. 10분의 루프에서는 기다리는 동안 컨텍스트가 흩어지고 다른 일에 손을 대게 됩니다. 2분의 루프는 "잠깐 기다리자"의 범위에 들어옵니다. 이 전환이 개발자의 편집 패턴을 바꿉니다.
두 번째 층은 팀 전체의 신뢰도입니다. 테스트가 빠르면 사람들이 테스트를 돌립니다. 테스트를 돌리면 깨짐이 자주 드러나고, 각각의 깨짐이 가진 변경 범위가 작아지며, 작은 변경 안에서 원인을 찾기 쉬워집니다. 역방향 순환이 정방향으로 뒤집힙니다. 단순한 속도 개선이 아니라 테스트 스위트가 조직에서 차지하는 역할의 변화입니다. 5화의 Rewrite Host와 4화의 타임머신이 개발자 개인의 이터레이션 속도를 높였다면, testcontainers 플러그인은 CI 수준에서 같은 이터레이션 속도를 가능하게 합니다.
이 모든 것이 본편 5화의 원리 위에서 돌아갑니다. 테스트 코드는 "무엇을" 검증할지만 알고, "어디서"(어느 컨테이너의 어느 스키마)는 BuildService가 주입합니다. 그 주입의 모양을 variant 데이터 클래스가 규정하고, variant 간 공유/격리 경계를 플러그인이 지탱합니다.
다섯 축, 다섯 교체, 하나의 원리
이 시리즈가 다뤄 온 다섯 축을 겹쳐 놓으면 놀라운 대칭이 드러납니다. 배포 축에서는 같은 Helm 템플릿을 쓰면서 values 파일을 갈아 끼웁니다. 클라우드 축에서는 같은 제품 모듈을 쓰면서 클라우드 Adapter를 갈아 끼웁니다. 시간 축에서는 같은 비즈니스 코드를 쓰면서 Clock Adapter를 갈아 끼웁니다. 공간 축에서는 같은 Gateway를 쓰면서 라우팅 대상을 갈아 끼웁니다. 테스트 축에서는 같은 테스트 코드를 쓰면서 variant를 갈아 끼웁니다.

갈아 끼우는 대상은 매번 다릅니다. 어느 곳에서는 YAML 파일의 층, 어느 곳에서는 Kotlin 인터페이스의 구현체, 어느 곳에서는 HTTP 헤더의 존재 ��여부, 어느 곳에서는 데이터 클래스의 필드 조합입니다. 그러나 골격은 같습니다. 안쪽에 "무엇을"을 말하는 계약이 놓이고, 그 계약은 교체 가능한 접점을 한두 개 열어 두며, 그 접점에 꽂히는 것은 호출부·환경·빌드 시스템·요청 헤더가 결정합니다.
이 대칭이 우연이 아닌 이유는, 다섯 레이어를 설계한 것이 같은 팀, 같은 사고방식, 같은 코드 리뷰 문화이기 때문입니다. 한 레이어에서 경계를 깎는 데 익숙해진 팀은 다음 레이어에서도 자연스럽게 같은 일을 합니다. 배포에서 values 층을 만들던 손은 인프라에서 spec 모듈을 만들 때 같은 판단을 반복하고, 시간 축에서 Clock 인터페이스를 주입받던 습관은 공간 축에서 라우팅을 명시적 필터로 분리할 때 그대로 다시 나타납니다. 규율은 전염됩니다.
경계를 깎으면 실험의 속도가 붙는다
시리즈 전체를 한 문장으로 요약하면 이렇습니다. 경계를 깎는다는 것은 결국 교체 가능성을 만드는 일이고, 교체 가능성은 곧 실험의 속도로 돌아옵니다.
각 편의 결론에서 반복해 등장한 단어가 "이터레이션 속도"였습니다. 배포 롤백이 revert 한 번이라는 속도, 새 클라우드를 붙이는 비용이 Adapter 구현 하나라는 속도, 시간을 미래로 밀어 즉시 검증하는 속도, 공간을 내 노트북으로 당겨 와 디버깅하는 속도, CI 통합 테스트가 2분 안에 끝나는 속도. 모두 다른 모양의 속도지만, 근원에는 같은 설계 원리가 놓여 있습니다.
속도는 결국 "하루에 시도할 수 있는 실험의 수"로 귀결됩니다. 엔지니어링이란 가설을 세우고, 빠르게 검증하고, 틀렸다�면 빠르게 포기하고, 맞았다면 확신을 쌓는 일입니다. 경계가 흐릿한 시스템에서는 가설 하나를 검증하는 비용이 커서 하루의 실험 수가 적어지고, 경계가 명확한 시스템에서는 그 비용이 작아져 같은 시간에 더 많은 실험이 돌아갑니다. 두 시스템의 엔지니어링 품질은 1년이 지나면 비교할 수 없을 만큼 벌어집니다.
본 시리즈가 보여 준 다섯 레이어의 설계는 이 "실험 비용의 감소"를 구조적으로 보장하는 장치들입니다. 장치마다 기술 스택은 완전히 다르지만 같은 판단 기준을 공유합니다. 독자가 가장 가져갈 만한 것은 구체적인 도구의 디테일이 아니라 그 판단 기준입니다. 어느 축이든 내 시스템에 맞는 형태로 풀 수 있다면, 비용 구조가 달라지기 시작합니다.
"규모가 작은 팀에서 이 다섯 축을 한꺼번에 끌어오는 건 과한 일 아닌가"라고 느끼셨다면, 그 감각이 옳습니다. flex도 한 분기에 깎아 낸 것이 아니라 몇 년에 걸쳐 한 축씩 늘려 왔습니다. 소규모 팀이 오늘 한 걸음을 떼려면 배포 축과 시간 축 두 가지부터 시작하시길 권합니다. 배포 축은 투자 대비 효과가 가장 빠릅니다. 환경별 스크립트 두 벌을 하나의 Helm 차트와 두 개의 values 파일로 합치기만 해도 "dev와 prod의 차이를 한 diff로 본다"는 감각을 팀이 갖습니다. ArgoCD나 App-of-Apps까지 도입하지 않더라도 values 분리만으로 얻는 이득이 커서 인프라 부담이 거의 없습니다. 시간 축은 코드 규율로만 풉니다. 서비스 클래스가 Clock을 주입받도록 하고, LocalDateTime.now()를 리뷰에서 지적 대상으로 삼는 것—이 두 가지만으로 테스트 작성과 버그 재현이 눈에 띄게 쉬워집니다. 나머지 세 축—클라우드, 공간, 테스트 인프라—은 팀의 규모와 아픔의 위치에 따라 뒤에 붙이면 됩니다. 목표는 "다섯 축을 다 깎는 것"이 아니라 경계를 깎는 사고방식이 한 축에서 다음 축으로 전염되기 시작하는 지점에 닿는 것입니다. 한 축에서 그 습관이 자리 잡으면, 다음 축은 훨씬 적은 비용으로 따라옵니다.
그리고 본편 6화로
이 서브시리즈가 끝나는 지점은 다른 이야기의 시작점과 맞닿아 있습니다. 본편 6화는 "사람을 위한 규율이 AI 에이전트에게도 작동한다"는 장면을 다룹니다. 본 시리즈에서 다룬 다섯 축의 경계들—values 층, spec 인터페이스, Clock Port, Rewrite Host 헤더, variant 데이터 클래스—은 사람이 읽고 지키기 위한 규율이지만, AI 에이전트도 같은 구조를 똑같이 읽어 냅니다. 경계가 깎여 있는 코드베이스에서 AI가 보는 풍경은 경계가 흐릿한 코드베이스의 풍경과 전혀 다릅니다.
경계를 깎는 일이 어떻게 AI-ready 한 코드베이스를 만들고, 그 코드베이스가 어떻게 코드 리뷰의 병목을 옮기고 있는지는 본편 6화에서 이어집니다. 다섯 축을 따라 내려온 이 여정이 독자의 시스템 위에서 한 축의 경계라도 깎기 시작하는 계기가 되기를 바랍니다. 한 축이 깎이면, 나머지는 따라옵니다.
본편 5화 "코드가 환경을 모르는 구조"에서 갈라져 나온 이야기, 여기서 매듭을 짓습니다.
🚀플렉스팀 채용페이지 바로가기☕flex Private Talk 신청하기공유하기





