[AI가 읽을 수 있는 코드베이스 1/5] 프롬프트보다 구조가 먼저다

AI를 도입하지 않으면 뒤처지는 걸까
솔직한 이야기를 해보겠습니다. 요즘 엔지니어링 팀에서 가장 흔한 감각은 불안입니다. AI 코딩 에이전트를 제대로 활용하지 못하면 뒤처질 것 같다는 느낌. 경쟁사는 이미 에이전트로 PR을 뽑아내고 있다는 소문. 우리 팀도 빨리 뭔가 해야 하지 않을까.
그래서 팀들이 움직이기 시작합니다. 커스텀 시스템 프롬프트를 다듬고, CLAUDE.md나 Cursor Rules 같은 프롬프트 가이드를 정비합니다. 에이전트 "스킬"을 조립하고, 하네스를 세팅하고, 워크플로우를 만듭니다. 이 방향이 틀린 건 아닙니다. 하지만 충분하지도 않습니다.
두려워할 것의 방향이 잘못되었을 수 있습니다. 프롬프트를 잘못 써서 뒤처지는 게 아닙니다. 에이전트가 기여할 수 있는 코드베이스 구조를 갖추지 못해서 뒤처집니다. 프롬프트 엔지니어링은 필요하지만, 에이전트 활용의 하한선을 결정하는 것은 코드베이스 구조입니다. 에이전트가 실제로 유의미한 코드를 생산하려면, 그 아래에 에이전트가 읽을 수 있는 구조가 있어야 합니다.
이 차이를 체감한 순간이 있습니다. 에이전트가 올린 PR을 열었을 때, 코드는 동작했습니다. 테스트도 통과했습니다. 그런데 리뷰를 시작하자 뭔가 어긋나 있었습니다. 팀이 오랫동안 지켜온 모듈 경계가 조용히 무너져 있었습니다. model 모듈에 인프라 의존성이 슬며시 들어와 있고, 서비스 간 직접 참조가 생겨 있었습니다. CLAUDE.md에 분명히 적혀 있는 규칙이었는데도요.
이 경험이 낯설지 않다면, 이 시리즈는 바로 그 이유와 해법을 다룹니다. 왜 자연어로 적은 가이드라인만으로는 에이전트를 가르칠 수 없는지, 그리고 무엇이 프롬프트보다 더 확실한 가드레일이 되는지. 문제는 자연어 지시가 가진 본질적 한계에서 시작됩니다.
자연어 가이드라인이 실패하는 세 가지 순간
1. 해석의 모호성
"model은 인프라에 의존하지 않는다"라는 문장을 에이전트가 읽었을 때, Spring Data의 @Id 어노테이션은 "인프라"인가요? Jackson의 @JsonProperty는요? 사람도 해석이 갈리는 경계에서, 에이전트는 더 쉽게 잘못된 판단을 내립니다.
2. 컨텍스트 윈도우의 한계
CLAUDE.md가 아무리 상세해도, 에이전트의 컨텍스트 윈도우에는 한계가 있습니다. 수백 줄의 아키텍처 가이드, 수천 줄의 코드를 동시에 처리하면서, "아, 이 의존성은 이 규칙 때문에 안 되는구나"를 추론하는 건 높은 인지 부하입니다. 에이전트가 코드 생성에 집중하다 보면 가이드라인의 세부 규칙을 놓치는 경우가 빈번합니다.
3. 피드백 부재
가장 치명적인 문제입니다. 에이전트가 가이드라인을 위반한 코드를 생성했을 때, 자연어 가이드라인은 아무런 피드백을 주지 않습니다. 에이전트는 자기가 규칙을 어겼는지조차 모릅니다. PR이 올라간 후 사람이 리뷰에서 발견하기 전까지, 위반은 조용히 누적됩니다.
빌드 가드레일: 에이전트에게 가장 명확한 피드백
flex의 Gradle 멀티모듈 + Hexagonal 구조에서는 이 문제가 근본적으로 다르게 풀립니다.
에이전트가 허용되지 않은 의존성을 추가하면 빌드가 실패합니다. 이건 말로 하는 피드백이 아니라, 컴파일러가 주는 명확한 피드백입니다.
> Task :issue:model:compileKotlin FAILED
e: file:///issue/model/src/main/kotlin/Issue.kt:3:8
Unresolved reference: springframework에이전트 입장에서는 "이건 안 된다"를 추론할 필요 없이, 빌드 결과를 보고 방향을 수정하면 됩니다. 에러 메시지 자체가 "왜 안 되는지"를 설명합니다 — model 모듈에 Spring 의존성이 없기 때문입니다.
이 차이를 도식으로 표현하면 다음과 같습니다.
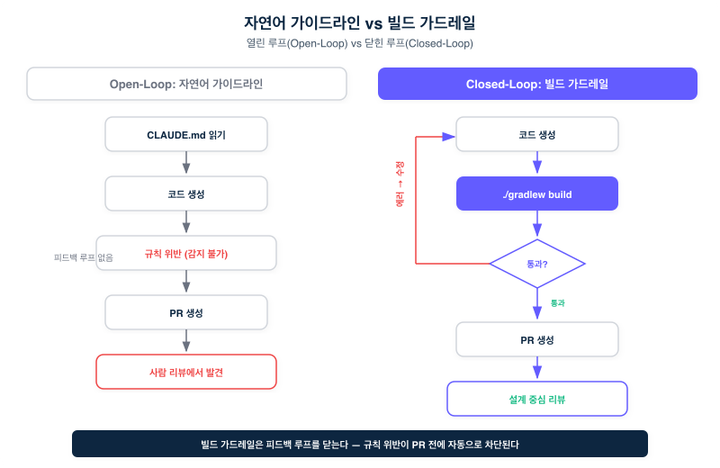
자연어 가이드라인은 열린 루프(open-loop)입니다. 에이전트가 규칙을 어겨도 즉각적 피드백이 없습니다. 빌드 가드레일은 닫힌 루프(closed-loop)입니다. 위반하면 즉시 빌드가 실패하고, 에이전트는 그 피드백을 보고 스스로 수정합니다.
CLAUDE.md의 역할과 한계
그렇다면 CLAUDE.md 같은 자연어 가이드라인은 필요 없는 걸까요? 그렇지 않습니다. 두 가지는 보완 관계입니다.
| 영역 | 빌드 가드레일이 담당 | CLAUDE.md가 담당 |
|---|---|---|
| 의존성 방향 | 모듈 간 허용된 의존성만 컴파일 가능 | "왜" 이런 방향인지 설명 |
| 코딩 스타일 | ktlint, detekt가 강제 | 팀 고유의 관례(네이밍, 패턴) 안내 |
| 모듈 구조 | type 선언 기반 자동 구성 |
각 모듈의 역할과 의도 설명 |
| 설계 판단 | 담당 불가 | 추상화 수준, 패턴 선택 가이드 |
| 비즈니스 컨텍스트 | 담당 불가 | 도메인 용어, 비즈니스 규칙 설명 |
빌드 가드레일은 "무엇이 불가능한지"를 정의합니다. CLAUDE.md는 "무엇이 바람직한지"를 안내합니다. 빌드가 막을 수 없는 영역 — 설계 판단, 추상화 수준, 비즈니스 맥락 해석 — 에서 자연어 가이드라인이 힘을 발휘합니다.
실제 백엔드 서비스의 CLAUDE.md는 이런 균형을 잘 보여줍니다.
## Development Philosophy
### Core Beliefs
- **Respect existing architecture** - Don't reinvent what works
- **Incremental progress over big bangs** - Small changes that compile and pass tests
- **Learning from existing code** - Study and plan before implementing이건 빌드로 강제할 수 없는 가치 판단입니다. 하지만 "compile and pass tests"라는 표현이 보여주듯, 빌드 가드레일의 존재를 전제하고 있습니다. CLAUDE.md는 빌드 위에 얹어지는 레이어입니다.
이 시리즈의 지도: AI 접근성 2축 평가 프레임워크
여기까지의 논지는 "프롬프트보다 구조가 중요하다"입니다. 이 주장을 한 번의 사례로 끝내지 않고 코드베이스 수준에서 평가하려면, 코드 품질과 AI 접근성을 분리해서 봐야 합니다.
flex는 코드베이스의 "AI 접근성"을 체계적으로 평가하기 위해 2축 프레임워크를 만들었습니다.
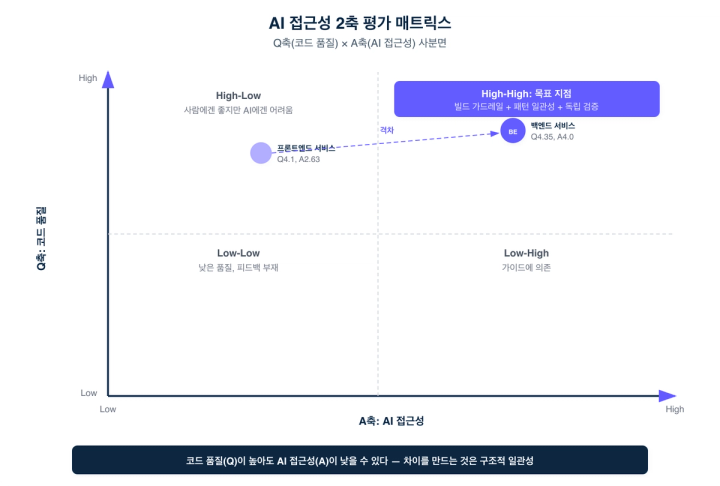
Q축: 코드 품질 (Code Quality)
전통적인 소프트웨어 품질 지표입니다. 테스트 커버리지, 순환 복잡도, 코드 중복률, 문서화 수준, 의존성 관리 등. 이 축이 높다고 AI가 잘 다룰 수 있는 건 아닙니다.
A축: AI 접근성 (AI Accessibility)
AI 에이전트가 코드베이스를 이해하고 수정할 수 있는 용이성입니다. 핵심 지표는 다음과 같습니다.
| 지표 | 설명 |
|---|---|
| 패턴 일관성 | 같은 종류의 문제를 같은 방식으로 풀고 있는가 |
| 빌드 피드백 품질 | 잘못된 코드에 대해 빌드가 명확한 에러를 주는가 |
| 모듈 경계 예측 가능성 | 에이전트가 "어디에 코드를 놓아야 하는지" 추론할 수 있는가 |
| 의존성 방향 강제 | 허용되지 않은 의존성이 물리적으로 차단되는가 |
| 독립 실행 가능성 | 전체 시스템 없이 부분을 검증할 수 있는가 |
| CLAUDE.md / 에이전트 가이드 | 빌드가 담당하지 못하는 설계 의도가 문서화되어 있는가 |
핵심 인사이트는 이것입니다: 코드 품질(Q축)이 높아도 AI 접근성(A축)이 낮을 수 있습니다. 코드가 잘 짜여 있지만 패턴이 비일관적이거나, 빌드 피드백이 부족하거나, 모듈 경계가 모호한 코드베이스는 사람에게는 좋아도 AI에게는 어렵습니다.
이 프레임워크의 등급 체계(L1~L5)와 실제 벤치마크 분석은 이후 5화에서 상세히 다룰 예정입니다.
실제 사례: 에이전트가 잘못된 의존성을 추가했을 때
백엔드 서비스의 Issue 도메인에서 실제로 벌어진 상황을 재구성하겠습니다.
에이전트에게 "Issue 모델에 생성일시 필드를 추가해줘"라는 요청이 갔습니다. 에이전트는 다음과 같은 코드를 생성했습니다.
// issue/model 모듈에 생성한 코드
package com.example.issue.model
import java.time.Instant
import org.springframework.data.annotation.CreatedDate // ← 문제의 import
data class Issue(
val id: Long,
val title: String,
@CreatedDate
val createdAt: Instant,
)@CreatedDate는 Spring Data의 어노테이션입니다. 하지만 issue:model 모듈의 build.gradle.kts에는 Spring Data 의존성이 없습니다. 빌드 결과는 즉각적이었습니다.
e: Unresolved reference: CreatedDate에이전트는 이 에러를 보고, model에 Spring Data를 추가하려고 시도합니다. 하지만 flex의 Convention Plugin은 type=kotlin-lib인 model 모듈에 Spring Data 계열 의존성 추가를 허용하지 않습니다. 에이전트는 두 번째 피드백을 받고, 결국 올바른 방향을 찾습니다.
// 수정된 코드: model에는 순수 Kotlin만
data class Issue(
val id: Long,
val title: String,
val createdAt: Instant, // 어노테이션 없이 순수 필드
)@CreatedDate 처리는 repository-jdbc 모듈의 매핑 로직에서 담당합니다. 빌드가 에이전트를 올바른 아키텍처 방향으로 유도한 것입니다.
에이전트 루프의 비용과 속도
여기서 자연스러운 질문이 나옵니다. "빌드 실패 → 수정 → 재빌드" 루프가 느리지 않은가?
이건 전통적인 사람-컴퓨터 인터랙션 모델에서는 맞는 걱정입니다. 하지만 AI 코딩 에이전트의 동작 모델에서는 다릅니다.
- 대기 비용의 성격이 다릅니다. 사람처럼 컨텍스트를 잃고 다시 몰입하는 비용이 아니라, 빌드 실패 후 에러를 분석해 다음 수정을 생성하는 기계적 루프에 가깝습니다.
- 피드백의 품질이 루프 횟수를 결정합니다. 컴파일 에러는 위치와 원인이 명확하기 때문에, 단순한 경계 위반은 1~2회 루프로 해결되는 경우가 많습니다.
- 빌드가 없으면 더 비쌉니다. 빌드 가드레일 없이 잘못된 코드가 PR까지 올라가면, 사람이 리뷰하고 → 코멘트 남기고 → 에이전트가 수정하고 → 다시 리뷰하는 루프가 됩니다. 이쪽이 훨씬 느립니다.
빌드 가드레일의 진짜 비용 절감은 "빠른 실패"에 있습니다. 잘못된 방향으로 100줄을 작성하기 전에, 3줄째에서 빌드가 멈춥니다.
다음 화: 빌드 피드백이 AI를 가르친다. 컴파일 에러, 의존성 미해결, ktlint 위반, 테스트 실패 — 각각의 빌드 피드백이 에이전트에게 어떤 품질의 정보를 전달하는지, 실제 에러 메시지와 에이전트의 수정 패턴으로 분석합니다. (2축 프레임워크의 A축: 빌드 피드백 품질)
🚀플렉스팀 채용페이지 바로가기
☕flex Private Talk 신청하기