[AI가 읽을 수 있는 코드베이스 5/5] AI 접근성 등급으로 보는 코드베이스

코드 품질이 높으면 AI가 잘 다루는 걸까
좋은 코드베이스가 AI 코딩 에이전트에게도 좋은 코드베이스인가? 직관적으로는 "그렇다"고 생각하기 쉽습니다. 테스트 커버리지가 높고, 순환 복잡도가 낮고, 문서화가 잘 되어 있다면 AI도 잘 다룰 수 있지 않을까?
flex가 내부적으로 실행한 평가 결과는 이 직관에 반하는 데이터를 보여줬습니다. 코드 품질(Q축)과 AI 접근성(A축)은 같은 것이 아닙니다. 코드가 잘 짜여 있지만 AI 에이전트가 고전하는 코드베이스가 있고, 코드가 완벽하지 않지만 AI 에이전트가 효과적으로 작업하는 코드베이스가 있었습니다.
이 차이를 체계적으로 이해하기 위해 flex는 2축 평가 프레임워크를 만들었습니다.
2축 평가 프레임워크
이 프레임워크를 만들기 전에, 업계에서도 비슷한 질문을 던지고 있었습니다. CodeScene의 2026년 동료심사 연구("AI-Ready Code: How Code Health Determines AI Performance")는 "AI가 버그 없이 안전하게 작동하려면 Code Health 9.4/10 이상이 필요하다"는 것을 실증했습니다 — 업계 평균인 5.15점으로는 부족합니다. Stack Overflow 2025 Developer Survey(응답자 49,000명 이상)에서는 "AI 도구의 가장 큰 도전이 무엇인가"라는 질문에 "AI 솔루션이 거의 맞지만 정확하지 않다"(66%)가 1위였고, 기존 코드베이스에서 AI 도구 성능이 낮다는 응답이 다수를 차지했습니다. 이 데이터들은 코드 품질과 AI 작업 가능성을 분리해서 봐야 한다는 문제의식을 뒷받침합니다.
Q축: 코드 품질 (Code Quality)
전통적인 소프트웨어 품질 지표입니다.
| 지표 | 세부 항목 |
|---|---|
| 테스트 | 단위 테스트 커버리지, 통합 테스트 존재 여부, 테스트 안정성 |
| 복잡도 | 순환 복잡도(Cyclomatic Complexity), 인지 복잡도(Cognitive Complexity) |
| 중복 | 코드 중복률, Copy-Paste 탐지 |
| 문서화 | API 문서, 코드 주석, README 품질 |
| 의존성 | 의존성 최신성, 보안 취약점, 라이선스 호환성 |
| 아키텍처 | 계층 분리, 관심사 분리, SOLID 원칙 준수 |
이 지표들은 SonarQube, CodeClimate, Codacy 같은 도구로 측정할 수 있는, 이미 잘 알려진 영역입니다.
A축: AI 접근성 (AI Accessibility)
AI 에이전트가 코드베이스를 이해하고 수정할 수 있는 용이성입니다. 이 축은 전통적인 코드 품질과 다른 관점을 제공합니다.
| 지표 | 설명 | 근거 |
|---|---|---|
| 패턴 일관성 | 같은 종류의 문제를 같은 방식으로 푸는가 | arXiv 2026: AI가 "Modular Mirage"를 만든다 — 패턴이 비일관적이면 에이전트가 임의의 변형을 쌓는다 |
| 빌드 피드백 품질 | 잘못된 코드에 명확한 에러를 주는가 | ICLR 2024: self-repair 효과는 피드백의 질에 의해 제한된다. 컴파일러 등 심볼릭 피드백이 가장 효과적 |
| 모듈 경계 예측 가능성 | 새 코드가 어디에 가야 하는지 추론 가능한가 | ACM SIGPLAN 2025: LLM은 모듈 원칙을 내재화하지 못하며, 외부 제약 레이어가 필요하다 |
| 의존성 방향 강제 | 허용되지 않은 의존성이 물리적으로 차단되는가 | arXiv 2026: 프롬프트 표현만으로 구조적으로 완전히 다른 의존성 그래프가 생성됨 |
| 독립 실행 가능성 | 전체 없이 부분을 검증할 수 있는가 | Martin Fowler(2025): Computational controls(테스트, 린터, 타입 체커)가 Inferential controls보다 결정론적으로 우수 |
| 에이전트 가이드 | CLAUDE.md 등 에이전트 문서 존재와 품질 | JetBrains(2025): "에이전트는 인간이 추측할 수 있는 것도 명시적 안내가 필요하다" |
| 자동 acceptance | 코드 변경의 동작을 자동으로 증명 가능한가 | DORA 2025: AI 도입이 성과로 이어지는 조건 중 하나가 "AI-accessible internal data와 건강한 데이터 생태계" |
L1 ~ L5 등급 정의
두 축의 점수를 종합해 코드베이스를 5개 등급으로 분류합니다.
L1: AI-Hostile (1.0 ~ 1.9)
특징: AI 에이전트가 의미 있는 작업을 거의 할 수 없음
- 빌드 시스템이 없거나 불안정
- 모듈 구조가 없음 (단일 모듈에 모든 코드)
- 테스트가 거의 없거나 모두 깨져 있음
- 의존성 관리가 되지 않음 (버전 충돌, 순환 의존성)
- 코드 패턴이 비일관적 — 같은 문제를 매번 다른 방식으로 풀고 있음
에이전트에게 이런 코드베이스에서 작업을 시키면, 잘못된 코드를 생성하고도 빌드가 통과하는 상황이 빈번합니다. 피드백 루프가 존재하지 않으므로, 에이전트의 실수가 누적됩니다.
L2: AI-Tolerant (2.0 ~ 2.9)
특징: AI 에이전트가 간단한 작업은 가능하나, 복잡한 작업에서 높은 실패율
- 빌드는 존재하지만 가드레일이 약함
- 모듈 구조는 있지만 경계가 느슨함 (의존성 방향 위반이 허용됨)
- 테스트가 존재하지만 커버리지가 낮거나 불안정
- 패턴이 부분적으로 일관적 — 도메인에 따라 다른 패턴 사용
- 에이전트 가이드(CLAUDE.md)가 없거나 빌드와 정합성이 없음
L3: AI-Guided (3.0 ~ 3.6)
특징: AI 에이전트가 가이드라인을 따라 작업 가능하나, 자율적 판단은 제한적
- 일관된 빌드 시스템과 CI/CD
- 모듈 구조와 패턴이 대체로 일관적
- 테스트 커버리지가 적정 수준
- 코드 품질 도구(lint, 정적 분석) 사용
- 에이전트 가이드가 존재하고 유용하지만, 빌드 가드레일은 부분적
이 등급에서 AI 에이전트는 기존 패턴을 따라하는 작업은 잘 수행합니다. 하지만 새로운 패턴을 도입하거나 모듈 경계를 넘는 변경에서는 사람의 개입이 필요합니다.
L4: AI-Partnered (3.7 ~ 4.5)
특징: AI 에이전트와의 협업이 구조적으로 지원됨
- 빌드 가드레일이 아키텍처 규칙을 물리적으로 강제
- 모듈 경계가 명확하고 예측 가능
- 높은 패턴 일관성 — 새로운 도메인도 기존 패턴을 따라 생성 가능
- Standalone / 독립 실행 환경 존재
- E2E 테스트 / Acceptance 증명 인프라
- 에이전트 가이드와 빌드 가드레일이 상호 보완
이 등급에서 AI 에이전트는 자율적으로 코드를 생성하고 검증하고 PR을 만들 수 있습니다. 사람은 주로 설계 판단에 개입합니다.
L5: AI-Native (4.6 ~ 5.0)
특징: 코드베이스가 AI 에이전트를 일급 시민으로 설계에 반영
- L4의 모든 요소
- AI 에이전트의 워크플로우가 빌드 시스템에 통합
- 에이전트의 코드 변경이 자동으로 acceptance 증명을 거쳐 PR로 생성
- 에이전트 간 위임(agent-to-agent delegation) 지원
- 코드베이스의 변경 이력 자체가 AI 친화적으로 관리
이 기준에서 L5는 현재 flex가 관찰한 범위에서는 아직 지향점에 가깝습니다.
같은 Q축, 다른 A축
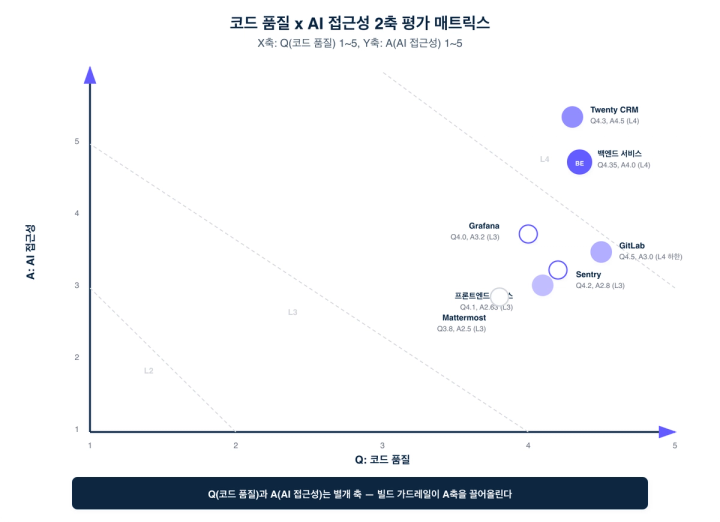
이 프레임워크를 실제 코드베이스에 적용하면 흥미로운 패턴이 드러납니다. Q축(코드 품질)이 비슷한 수준인 두 서비스가 A축(AI 접근성)에서 크게 갈리는 경우가 있습니다.
flex가 내부 서비스들을 평가했을 때, Q축 4점대로 유사한 두 서비스의 A축은 각각 4.0과 2.6으로 갈렸습니다. 코드 품질만 보면 비슷한 수준이었습니다. 좋은 컴포넌트 설계, 일관된 패턴, 적절한 테스트. 그런데 AI 접근성에서는 1.4점 차이가 났습니다.
핵심 원인은 의존성 방향의 물리적 강제 여부였습니다. A축이 높은 서비스는 Gradle Convention Plugin으로 "build.gradle.kts에 없으면 import 자체가 불가능"한 수준의 강제가 있었습니다. A축이 낮은 서비스는 TypeScript 컴파일 에러는 잡을 수 있었지만, 아키텍처 경계를 어긴 import는 컴파일을 통과했습니다. ESLint no-restricted-imports로 부분적 제한은 가능하지만, 빌드 시스템에 인코딩된 물리적 강제에는 미치지 못합니다.
결과적으로 에이전트가 잘못된 의존성을 추가했을 때, 한쪽은 빌드가 즉시 막고, 다른 쪽은 아무 피드백이 없습니다. 에이전트에게 즉각적 피드백이 없으므로, 잘못된 패턴이 조용히 누적됩니다.
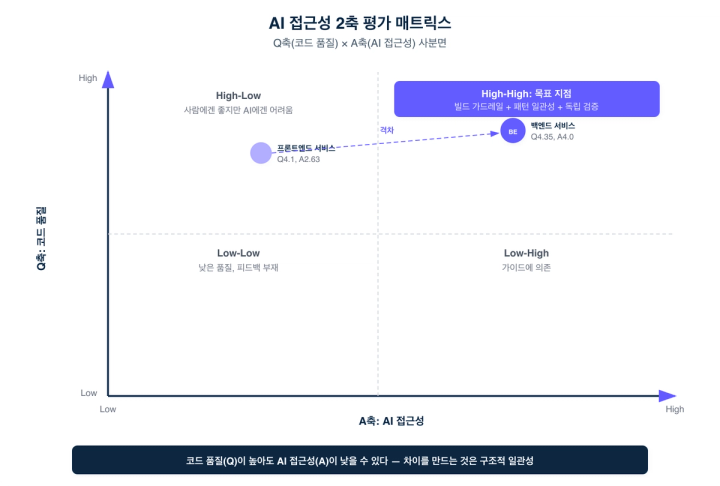
"코드 품질 != AI 접근성" — 구조적 일관성이 만드는 차이
이 평가에서 가장 중요한 인사이트는 이것입니다.
코드 품질이 높아도 AI 접근성은 낮을 수 있다. 차이를 만드는 것은 구조적 일관성이다.
이 인사이트는 flex만의 관찰이 아닙니다. CodeScene의 실증 연구는 일반적인 코드 품질 수준(평균 5.15/10)에서 AI를 사용하면 결함 위험이 최소 60% 증가한다는 것을 보였고, Stack Overflow 조사에서는 73%의 개발자가 기존 코드베이스에서 AI 도구 성능이 낮다고 응답했습니다.
구조적 일관성이란 다음을 의미합니다.
1. 패턴의 예측 가능성
에이전트가 10번째 도메인의 코드를 생성할 때, 앞의 9개 도메인에서 같은 패턴이 반복되었다면 올바른 코드를 생성할 확률이 높습니다. flex의 공통 모듈 골격 기반 도메인 구조가 이 예측 가능성을 제공합니다.
2. 피드백의 물리적 보장
컨벤션은 잊을 수 있지만, 빌드 실패는 무시할 수 없습니다. Convention Plugin이 아키텍처 규칙을 빌드 시스템에 인코딩하면, 에이전트에게 일관되고 즉각적인 피드백이 보장됩니다.
3. 조립 가능한 검증 환경
Standalone 환경과 E2E 인프라가 있으면, 에이전트가 자기 작업의 완결성을 스스로 증명할 수 있습니다. 이것이 L4와 L3를 가르는 핵심 차이입니다.
L4에서 L5로 — 남은 과제
백엔드 서비스가 L4에서 L5로 가려면 무엇이 필요할까요?
| 현재 (L4) | 목표 (L5) | 과제 |
|---|---|---|
| 일부 도메인에 Standalone | 모든 도메인에 Standalone | standalone-app 확대 |
| E2E 부분 커버리지 | 전 도메인 E2E 커버리지 | 테스트 시나리오 확장 |
| 에이전트가 PR 생성 | 에이전트가 자동으로 E2E + Demo + PR | 워크플로우 자동화 |
| 단일 에이전트 | 에이전트 간 위임 | 에이전트 위임 레이어 활용 |
| CLAUDE.md 수동 관리 | 빌드와 CLAUDE.md 자동 동기화 | 메타 프로그래밍 |
L5는 코드베이스가 AI 에이전트를 일급 시민(first-class citizen)으로 설계에 반영하는 수준입니다. 에이전트의 워크플로우가 빌드 시스템에 네이티브하게 통합되고, 에이전트 간 협업이 구조적으로 지원되며, 코드베이스의 변경 이력 자체가 AI 친화적으로 관리됩니다.
공개적으로 확인된 L5 사례는 아직 찾기 어렵습니다. 하지만 flex의 구조 — Convention Plugin, Standalone 환경, Acceptance 인프라, 에이전트 위임 레이어 — 는 L5를 향한 구체적인 경로를 보여줍니다.
브라운필드에서 AI 에이전트가 실패하는 이유
이 등급 체계가 추상적인 표에 머물지 않는 이유는 브라운필드에서 분명해집니다. 오래된 코드베이스에서 에이전트가 어디서 실패하는지를 설명하는 렌즈가 되기 때문입니다.
AI 에이전트가 가장 빛나는 순간은 그린필드입니다. 빈 저장소, 새 프로젝트, 백지에서 시작하는 코드. 에이전트에게 아키텍처를 설명하고 첫 번째 모듈을 만들어달라고 하면, 놀라울 정도로 깔끔한 결과가 나옵니다. 컨텍스트가 단순하고, 기존 코드와의 충돌이 없으며, 에이전트가 전체를 파악할 수 있기 때문입니다.
브라운필드는 다른 이야기입니다. 수년간 쌓인 코드, 수십 명이 기여한 히스토리, 문서화되지 않은 암묵적 규칙. 여기에 에이전트를 투입하면 그린필드에서는 보이지 않았던 실패 패턴이 나타납니다.
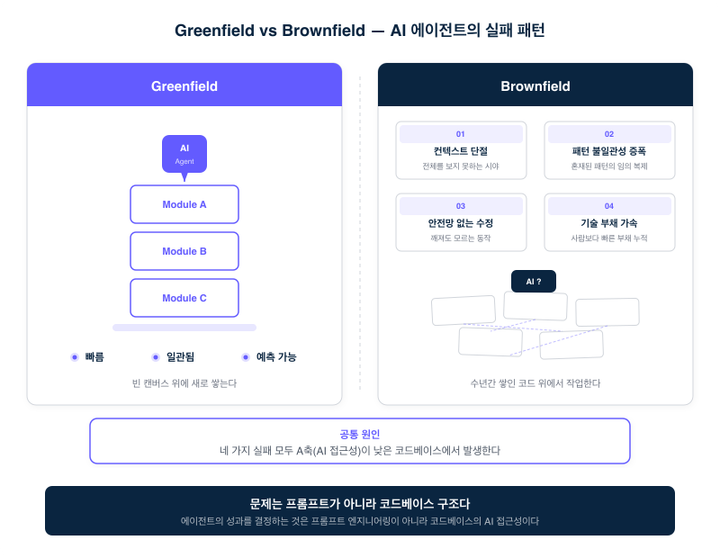
컨텍스트 단절. 코드베이스가 커질수록 에이전트는 전체를 파악하지 못합니다. 컨텍스트 윈도우 안에 들어온 파일만 보고 판단하다가, 멀리 떨어진 모듈과의 관계를 놓칩니다. 이 모듈이 저 모듈의 이벤트를 구독하고 있다는 사실, 이 설정 값이 다른 서비스의 동작을 결정한다는 사실 — 로컬 컨텍스트만으로는 보이지 않는 연결이 브라운필드에는 무수히 존재합니다.
패턴 불일관성의 증폭. 오래된 코드베이스에는 시기별로 다른 패턴이 혼재합니다. 에이전트는 참조할 코드를 고를 때 어떤 패턴이 현재 표준인지 판단하지 못합니다. 초기에 작성된 코드의 패턴을 따라하기도 하고, 자신이 학습한 일반적 패턴을 새로 도입하기도 합니다. 결과적으로 이미 혼재된 패턴 위에 또 다른 변형이 쌓입니다.
안전망 없는 수정. 빌드 가드레일과 테스트가 부족한 코드베이스에서, 에이전트는 동작을 깨뜨려도 즉시 알 수 없습니다. 컴파일은 통과하지만 런타임에서 실패하는 변경, 다른 모듈의 동작을 미묘하게 바꾸는 수정. 에이전트는 빌드가 성공했으므로 "완료"로 보고합니다. 문제가 드러나는 건 훨씬 나중입니다.
기술 부채의 가속. 구조적 문제가 있는 코드베이스에서 속도만 빠른 에이전트는 기술 부채를 사람보다 빠르게 쌓습니다. 잘못된 위치에 코드를 생성하고, 불필요한 의존성을 추가하고, 중복 로직을 만들어내는 일이 사람의 손보다 빠른 속도로 일어납니다. 에이전트의 생산성이 높을수록 부채 누적 속도도 비례합니다.
네 가지 실패 패턴의 공통 원인은 하나입니다. 모두 A축(AI 접근성)이 낮은 코드베이스에서 발생합니다. 빌드 가드레일이 약하고, 모듈 경계가 모호하고, 패턴이 비일관적인 코드베이스. 에이전트의 능력이 아니라 코드베이스의 구조가 실패를 결정합니다.
그린필드에서의 생산성은 시간이 지날수록 기본값에 가까워집니다. 모델이 좋아질수록, 빈 프로젝트에서 빠르게 코드를 만들어내는 능력은 점점 보편화됩니다. 차이를 만드는 건 브라운필드입니다. 수년간 쌓아온 코드베이스에서 에이전트가 안전하게 기여할 수 있는 구조 — 명확한 모듈 경계, 물리적 의존성 강제, 일관된 패턴, 빌드 피드백 루프. 이것이 오래된 코드베이스가 가질 수 있는 진짜 자산입니다.
시리즈를 마치며
다섯 편에 걸쳐 "AI가 읽을 수 있는 코드베이스"를 이야기했습니다.
1화에서 자연어 가이드라인과 빌드 가드레일의 차이를 이야기했고, 2화에서 빌드 피드백의 유형과 품질을 분석했습니다. 3화에서 Standalone App이 어떻게 도메인을 독립 실행 가능하게 조립하는지를 실제 코드로 보여줬고, 4화에서 Acceptance 증명이 Code Review를 어떻게 바꾸는지를 다뤘습니다. 마지막으로 본 글에서 이 모든 것을 2축 평가 프레임워크로 종합했습니다.
관통하는 인사이트는 하나입니다.
구조적 일관성이 AI 접근성을 만든다.
이것은 본편 1화에서 이야기한 "사람을 위한 규율이 AI에도 작동한다"의 구체적 메커니즘입니다. 본편 1화에서 깎아낸 모듈 경계가, 본편 6화에서 AI 에이전트의 가드레일이 됩니다. 그 사이의 인과 사슬 — 이벤트 인프라, 인가 시스템, 멀티클라우드, 타임머신 — 을 모두 관통하는 것은 "빌드가 지킨다"라는 하나의 원칙입니다.
AI 코딩 에이전트의 시대에, 가장 중요한 아키텍처 투자는 새로운 도구를 도입하는 것이 아닙니다. 이미 존재하는 빌드 규율, 모듈 경계, 패턴 일관성을 AI 에이전트도 읽을 수 있는 형태로 체계화하는 것입니다.
코드 품질과 AI 접근성. 이 두 축이 모두 높은 코드베이스를 만드는 것이, 지금 엔지니어링 팀이 할 수 있는 가장 높은 레버리지의 투자입니다.
🚀플렉스팀 채용페이지 바로가기
☕flex Private Talk 신청하기