[의존성의 방향을 따라 4/5] PR을 전파하는 Distributer

코드가 바뀌었다. 그 다음은?
3화에서 Updater가 OpenRewrite와 Claude를 사용해 코드를 변환했습니다. 변환된 코드는 아직 로컬 브랜치에만 존재합니다. 이 변경을 실제로 각 레포에 반영하려면, PR을 생성하고, CI를 통과시키고, 리뷰를 받고, 머지해야 합니다.
50개 이상의 레포에서 이 과정을 수동으로 관리하는 것은 불가능합니다. 한 레포의 PR 하나를 챙기는 일은 어렵지 않습니다 — CI 한 번 보고, 리뷰 한 번 받고, 머지 버튼 한 번 누르면 됩니다. 문제는 그게 50번이고, 그 50개가 서로 머지 순서에 제약을 갖는다는 데 있습니다. 한두 개는 사람이 머릿속으로 추적할 수 있지만, 수십 개의 PR이 각자 다른 CI 상태와 리뷰 단계에 흩어져 있으면, "지금 머지해도 되는 PR이 무엇인가"라는 질문에 답하는 것조차 일이 됩니다. Distributer는 이 전파 과정 전체를 자동화합니다. 코드 변환이 Updater의 영역이었다면, 그 변환을 현실의 레포에 안착시키는 운영이 Distributer의 영역입니다.
Wave 기반 전파 모델
2화에서 Planner가 의존 그래프를 위상 정렬하여 Wave를 생성했습니다. Distributer는 이 Wave 순서에 따라 PR을 전파합니다.
핵심 규칙은 단순합니다. 현재 Wave의 모든 PR이 머지되어야, 다음 Wave의 PR이 생성된다.
전파 시퀀스
Spring Boot 3.5.5에서 3.5.10 업그레이드를 예로 들겠습니다.
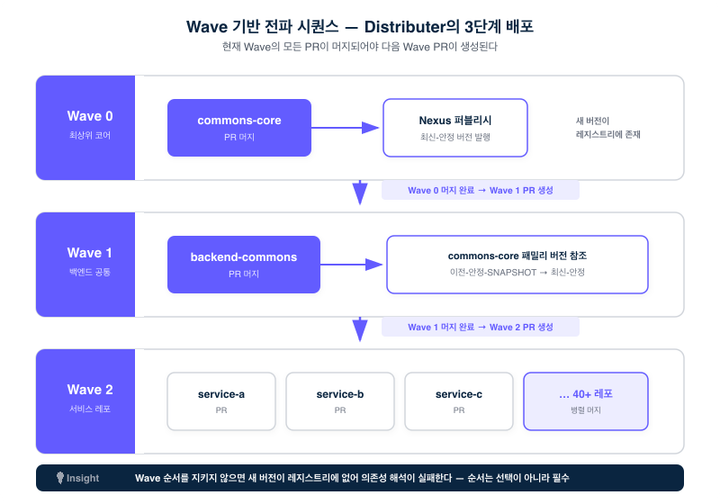
Wave 간 의존 관계가 중요한 이유
Wave 0에서 commons-core의 PR이 머지되면, 새 버전 최신-안정이 Nexus에 퍼블리시됩니다. Wave 1의 backend-commons는 이 새 버전을 자신의 의존성 선언에서 참조해야 합니다. backend-commons의 PR에는 commons-core의 패밀리 버전을 이전-안정-SNAPSHOT에서 최신-안정으로 올리는 변경이 포함됩니다.
만약 Wave 0이 완료되기 전에 Wave 1의 PR을 생성하면, 최신-안정 버전이 아직 Nexus에 존재하지 않으므로, 의존성 해석이 실패합니다. 빌드가 깨지고, CI가 실패합니다. Wave 순서를 지키는 것은 선택이 아니라 필수입니다.
이 제약은 사람이 수동으로 버전업할 때도 똑같이 존재했습니다. 다만 그때는 그 제약이 누구의 머릿속에도 명시적으로 적혀 있지 않았고, "왜 내 빌드만 깨지지?"라는 의문으로 뒤늦게 드러났을 뿐입니다. 1화 슬랙 로그에서 누군가 먼저 올린 commons를 다른 사람이 아직 못 받아 충돌하던 장면이 바로 이 순서 위반의 증상이었습니다. Distributer는 이 암묵적 규칙을 Wave라는 게이트로 명시화합니다. 머릿속 규칙은 잊히고 어겨지지만, 게이트는 어길 방법이 없습니다.
PR 생성 전략
Distributer가 PR을 생성할 때 포함하는 정보를 보겠습니다.
PR 구조
PR 제목에 [Evergreen] 접두사가 붙어서, 자동 생성된 PR임을 식별할 수 있습니다. Recipe 적용 내역과 AI 수정 사항이 분리되어 있어서, 리뷰어가 어디에 집중해야 하는지 명확합니다.
## [Evergreen] Spring Boot 3.5.5 -> 3.5.10 Upgrade
### 변경 사항
- Spring Boot 3.5.5 -> 3.5.10
- MySQL Connector/J 9.1.0 -> 9.2.0 (커넥션 릭 수정)
- FixtureMonkey 1.1.7 -> 1.1.11 (Jackson 호환성)
### 적용된 Recipe
- `com.example.SpringBoot3_5_10`
- `com.example.UpgradeMySQLConnector`
- `com.example.UpgradeFixtureMonkey`
### AI 수정 사항
- `IssueService.kt:42` — nullable 반환 처리 추가
- `ThreadService.kt:28` — 메서드명 대소문자 수정
### Wave 정보
- Wave: 2/3
- 선행 조건: backend-commons 다음-버전 퍼블리시 완료
### 자동 머지 조건
- [ ] CI 통과
- [ ] 코드 리뷰 승인 (1명 이상)리뷰어가 봐야 할 것
여기서 PR 본문의 구조가 리뷰의 성격 자체를 바꿉니다. recipe가 적용한 변경은 정적 변환이므로, 리뷰어가 하나하나 검토할 필요가 적습니다. recipe 자체가 이미 테스트를 통과했고, 같은 변환이 다른 49개 레포에도 똑같이 적용되었기 때문입니다 — 한 곳에서 옳다면 전부에서 옳고, 한 곳에서 틀렸다면 recipe를 고쳐 전부 다시 돌립니다. 리뷰어가 레포마다 같은 diff를 50번 들여다보는 건 시간 낭비일 뿐 아니라, 반복되는 똑같은 변경 속에서 정작 중요한 차이를 놓치게 만듭니다. 그래서 리뷰어가 집중해야 할 부분은 AI 수정 사항입니다. 결정론적 변환과 판단이 개입한 변환을 PR 본문에서 미리 갈라놓는 것은, 리뷰어의 주의력을 정확히 위험이 있는 곳으로 몰아주기 위한 설계입니다.
리뷰 우선순위:
1. AI 수정 사항 → 비즈니스 로직 판단이 맞는지 확인
2. Recipe 예외 케이스 → recipe가 의도와 다르게 변환한 곳이 없는지
3. 의존성 버전 → 새 버전이 올바른지 (보통 recipe가 처리)CI 상태 추적
50개 이상의 레포에서 PR이 생성되면, 각 PR의 CI 상태를 추적해야 합니다. Distributer는 이 상태를 중앙에서 모니터링합니다.
상태 머신
각 PR은 다음 상태를 거칩니다.
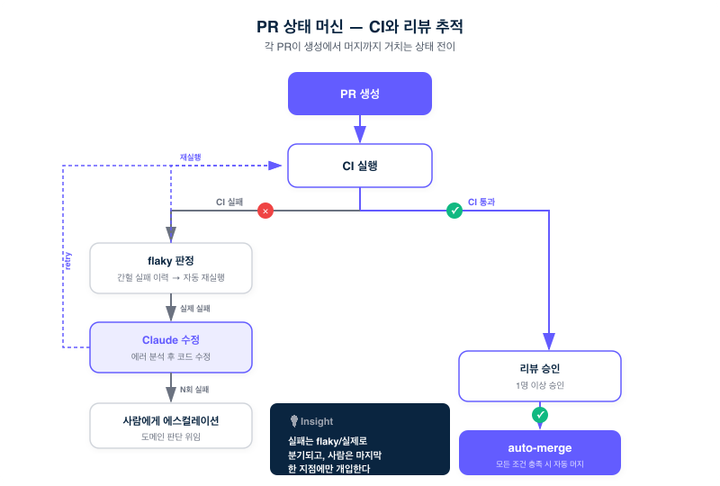
Flaky Test 처리
자동화에서 가장 다루기 까다로운 건 "진짜 실패"가 아니라 "가짜 실패"입니다. CI 실패 원인 중 상당수는 flaky test — 코드와 무관하게 타이밍이나 외부 상태에 따라 간헐적으로 깨지는 테스트입니다. 사람이라면 "아, 얘 가끔 이래" 하고 한 번 더 돌려보지만, 자동화가 이걸 구분하지 못하면 멀쩡한 PR을 실패로 처리하거나, 반대로 실패를 무조건 재시도하다가 진짜 버그를 흘려보냅니다. Distributer는 실패한 테스트가 이전에도 간헐적으로 실패한 이력이 있는지 확인하고, flaky로 판단되면 자동으로 재실행합니다. 핵심은 "재실행하느냐"가 아니라 "재실행해도 되는지를 이력에 근거해 판단하느냐"입니다.
CI 실패 분석 흐름:
1. 빌드 로그에서 실패한 테스트 식별
2. 해당 테스트의 최근 30일 이력 조회
3. 간헐적 실패 이력이 있으면 -> 자동 재실행 (최대 2회)
4. 이력이 없으면 -> 실제 변경에 의한 실패로 판단
5. 실제 실패 -> Claude 수정 시도 또는 에스컬레이션Auto-merge 정책
모든 조건이 충족되면 Distributer가 자동으로 PR을 머지합니다.
머지 조건
auto-merge 조건:
1. CI 전체 통과 (컴파일 + 테스트 + lint + 정적 분석)
2. 코드 리뷰 승인 (최소 1명)
3. Wave 선행 조건 충족 (이전 Wave의 모든 PR 머지 완료)
4. dependency lock 검증 통과
5. 충돌 없음Wave 2의 병렬 머지
Wave 2에서는 40개 이상의 서비스 레포 PR이 동시에 존재합니다. 이 레포들은 서로 의존하지 않으므로, 머지 순서에 제약이 없습니다. CI가 통과하고 리뷰가 승인되는 순서대로 머지됩니다.
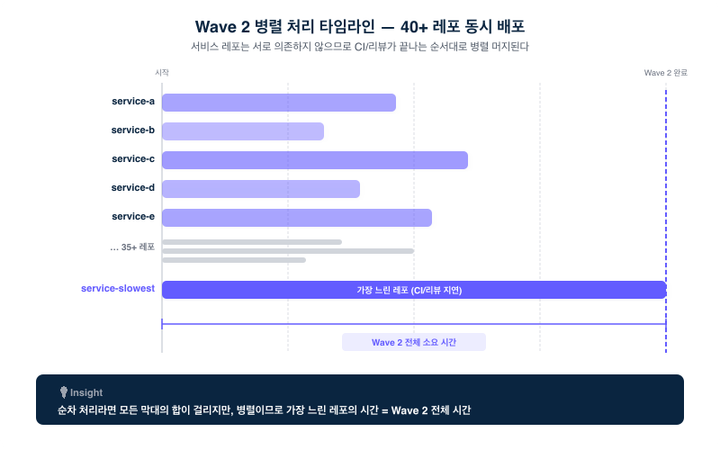
병렬 처리 덕분에, Wave 2의 40개 레포가 순차적으로 처리되는 것보다 훨씬 빠르게 완료됩니다. 가장 느린 레포의 소요 시간이 Wave 2 전체의 소요 시간이 됩니다. 순차 처리에서는 시간이 레포 수에 비례해 쌓이지만(40개면 40배), 병렬에서는 가장 오래 걸리는 한 개의 시간으로 수렴합니다. 1화에서 본 "담당자 1-4시간 × 40개 레포"라는 곱셈이, 여기서 "가장 느린 한 개 + 약간의 오버헤드"라는 덧셈으로 바뀝니다. 의존하지 않는 것들을 굳이 줄 세우지 않는 것 — Wave 모델이 노리는 효율의 정체입니다.
실패 시 에스컬레이션
자동화가 풀지 못하는 문제는 사람에게 넘겨야 합니다. 에스컬레이션 기준과 방식을 정리합니다.
에스컬레이션 기준
| 상황 | Claude 시도 | 에스컬레이션 기준 |
|---|---|---|
| 컴파일 에러 | 최대 3회 | 3회 실패 시 |
| 테스트 실패 | 최대 2회 | 2회 실패 시 (flaky 제외) |
| 리뷰 수정 요청 | 최대 1회 | 1회 실패 시 (사람의 판단이 필요한 영역) |
| dependency 충돌 | 시도하지 않음 | 즉시 에스컬레이션 |
| CI 인프라 문제 | 자동 재시도 3회 | 3회 실패 시 |
에스컬레이션 알림
[Evergreen] service-payroll Spring Boot 3.5.10 업그레이드 실패
상태: 에스컬레이션 (Claude 3회 수정 실패)
Wave: 2/3
PR: https://github.com/example/service-payroll/pull/1234
실패 원인:
- PayrollCalculationServiceTest.kt:156
- assertThat(result.totalAmount).isEqualTo(expected)
- Expected: 1000000, Actual: 999999
- Claude 분석: 부동소수점 정밀도 이슈로 추정되나,
비즈니스 정확성 판단이 필요하여 에스컬레이션
담당자: @team-payroll에스컬레이션 알림에는 Claude가 왜 실패했는지와 사람이 무엇을 판단해야 하는지가 포함됩니다. 사람은 전체 변경을 검토하는 것이 아니라, 자동화가 풀지 못한 특정 지점만 확인하면 됩니다.
여기서 사람의 위치가 분명해집니다. 사람은 전 과정에 묶여 50개 레포를 일일이 처리하지도(수동 프로세스), 모든 판단에서 빠져 검증 없는 변경을 흘려보내지도(전적인 AI 위임) 않습니다. 비즈니스 정확성처럼 자동화가 결정할 수 없는 좁은 지점에만 투입됩니다. 위 예시의 부동소수점 차이가 버그인지 의도된 반올림인지는 recipe도 Claude도 단정할 수 없습니다 — 도메인 맥락을 아는 사람만 판단할 수 있고, 시스템은 바로 그 지점만 사람에게 넘깁니다.
에스컬레이션 비율 목표
목표 에스컬레이션 비율:
- 패치 버전업: < 5% (50개 중 2-3개)
- 마이너 버전업: < 15% (50개 중 7-8개)
- 메이저 버전업: < 30% (50개 중 15개)패치 버전업에서 에스컬레이션 비율이 5%를 초과하면, recipe 품질에 문제가 있다는 신호입니다. recipe를 개선하고, 다음 번 같은 유형의 변경에서 에스컬레이션 비율이 낮아지도록 피드백 루프를 돌립니다.
전파 완료 보고
모든 Wave가 완료되면, Distributer가 전체 전파 결과를 보고합니다.
[Evergreen] Spring Boot 3.5.5 -> 3.5.10 전파 완료
시작: 2026-03-24 09:00
완료: 2026-03-24 17:30
소요: 8시간 30분
Wave 0 (commons-core): 완료
- PR #456 머지 (09:00 - 10:15)
- 최신-안정 퍼블리시 완료
Wave 1 (backend-commons): 완료
- PR #789 머지 (10:20 - 12:00)
- 다음-버전 퍼블리시 완료
Wave 2 (서비스 레포 42개): 완료
- 자동 머지: 39개
- 에스컬레이션 후 수동 머지: 3개
- service-payroll (부동소수점 테스트)
- service-billing (deprecated 내부 API)
- service-insight (OpenSearch 호환성)
적용된 Recipe: com.example.SpringBoot3_5_10
Claude 수정: 총 27개 파일 (17개 레포)
에스컬레이션 비율: 7.1% (3/42)1화에서 "수동으로 2-4주"였던 작업이, 하루 안에 완료됩니다. 그리고 이 보고서 자체가 부수적 산물입니다 — 어느 레포가 자동으로 끝났고, 어디서 사람이 무엇을 판단했고, 에스컬레이션 비율이 얼마였는지가 한 장에 남습니다. 1화의 스프레드시트 수동 관리와 비교하면, 추적이라는 별도의 노동이 통째로 사라진 셈입니다. 다음 같은 유형의 버전업에서 무엇을 개선할지도 이 기록에서 출발합니다.
Distributer가 가능한 이유
Distributer의 자동화가 가능한 전제 조건을 정리합니다.
- 일관된 CI 파이프라인: 모든 레포가 같은 빌드 구조를 따르므로, CI 상태를 동일한 방식으로 판단할 수 있습니다.
- 일관된 PR 규칙: 모든 레포가 같은 branch protection rule, 같은 리뷰 정책을 사용합니다.
- 일관된 퍼블리시 방식: 퍼블리시 컨벤션 플러그인이 모든 레포에서 동일한 방식으로 버전을 관리하고 퍼블리시합니다.
- DAG 구조의 의존 그래프: 순환이 없으므로, Wave 순서가 항상 결정 가능합니다.
이 모든 것이 본편 1화의 Convention Plugin에서 시작됩니다. 구조가 일관되지 않으면, PR 생성, CI 추적, 머지 정책 모두 레포마다 다르게 구현해야 하고, 그건 자동화가 아니라 또 다른 수동 작업입니다.
다음 화 — Evergreen이 가능했던 이유. 이 이야기 전체의 인과 사슬을 회수하고, Convention Plugin이 Evergreen의 전제인 이유를 정리합니다. Google, Spotify, Airbnb의 비슷한 사례와 비교합니다.
🚀플렉스팀 채용페이지 바로가기
☕flex Private Talk 신청하기