[의존성의 방향을 따라 5/5] Evergreen이 가능했던 이유

다시, 1화로
이 글들의 제목은 "의존성의 방향을 따라"입니다. 의존성이 향하는 방향을 따라 변경이 전파되고, 그 전파를 자동화하는 Evergreen 파이프라인을 네 편에 걸쳐 살펴봤습니다.
마지막 화에서는 한 발 물러서, 이 모든 것이 가능했던 구조적 전제를 짚겠습니다. 그리고 본편 이야기 전체의 인과 사슬이 여기서 어떻게 회수되는지 정리합니다.
Convention Plugin이 Evergreen의 전제인 이유
Evergreen의 세 구성요소가 각각 어떤 전제에 의존하는지 되짚어 보겠습니다.
Planner의 전제: 일관된 의존성 선언
2화에서 Planner가 의존 그래프를 자동 구축한다고 했습니다. 이게 가능한 이유는 버전 관리 플러그인이 모든 레포에서 동일한 의존성 선언 방식을 강제하기 때문입니다. 50개 이상의 레포가 모두 같은 형식으로 — 라이브러리 패밀리 버전을 그룹 ID 접두사로 묶어 지정하고, 개별 아티팩트 버전을 명시하는 — 의존성을 선언합니다.
만약 이 플러그인이 없었다면, 레포마다 다른 방식으로 의존성을 선언했을 것이고, Planner는 레포마다 다른 파서를 유지해야 했을 것입니다. 파서의 수가 레포 수에 비례하면, 그건 자동화가 아니라 또 다른 유지보수 부담입니다. 자동화가 줄이려던 "레포 수에 비례하는 노동"이, 자동화 도구 안으로 자리만 옮겨 그대로 남는 셈입니다. 일관성이라는 전제가 무너지는 순간, 도구의 복잡도가 문제의 복잡도를 그대로 빼닮아버립니다.
Updater의 전제: 일관된 빌드 구조
3화에서 OpenRewrite recipe가 모든 레포에 동일하게 적용된다고 했습니다. 이게 가능한 이유는 빌드 컨벤션 플러그인이 모든 레포에서 동일한 타입 시스템을 제공하기 때문입니다.
gradle.properties에 type=kotlin-boot-mvc-application만 선언하면,
의존성, 플러그인, 컴파일 옵션이 자동으로 구성됨.
-> 모든 레포의 빌드 구조가 동일
-> recipe 하나가 모든 레포에서 동일하게 작동레포마다 빌드 구조가 달랐다면, 레포당 별도 recipe가 필요했을 것입니다. 50개 레포에 50개 recipe를 관리하는 것은, 50개 레포를 수동으로 업그레이드하는 것과 비용이 크게 다르지 않습니다.
Distributer의 전제: 일관된 CI/CD 파이프라인
4화에서 Distributer가 PR 생성, CI 추적, auto-merge를 자동화한다고 했습니다. 이게 가능한 이유는 모든 레포가 동일한 CI 파이프라인, 동일한 branch protection, 동일한 퍼블리시 방식을 따르기 때문입니다.
퍼블리시 컨벤션 플러그인이 모든 레포에서:
- 동일한 버전 관리 체계 (SNAPSHOT -> Release)
- 동일한 퍼블리시 흐름 (Nexus)
- 동일한 Git 태깅 규칙 (v{version})인과 사슬
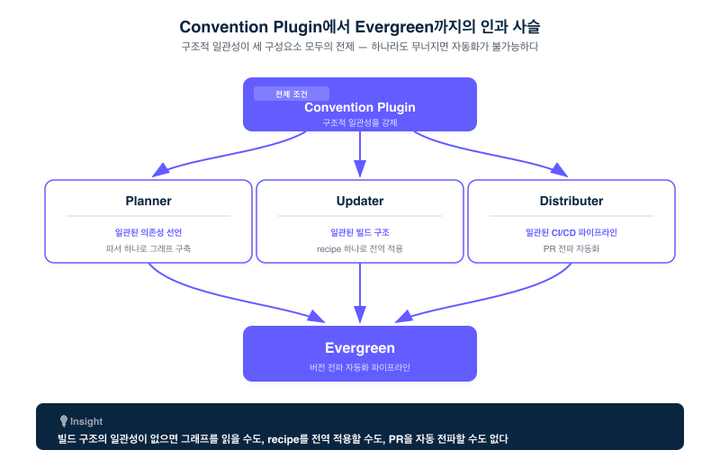
Convention Plugin은 Evergreen의 전제 조건입니다. 빌드 구조의 일관성이 없으면, 의존 그래프를 자동으로 읽을 수 없고, recipe를 전역으로 적용할 수 없고, PR을 자동으로 전파할 수 없습니다. 세 구성요소가 각자 다른 일을 하지만, 모두 같은 한 가지 가정 위에 서 있다는 점이 중요합니다 — "어느 레포를 집어도 모양이 같다." 이 가정이 깨지면 셋 다 동시에 무너집니다. 그래서 Evergreen은 사실 Planner·Updater·Distributer라는 세 도구의 합이라기보다, 구조적 일관성이라는 토대 위에 세운 하나의 건축물에 가깝습니다.
본편 이야기의 인과 사슬, 최종 회수
본편 7편의 인과 관계를 최종 정리합니다.
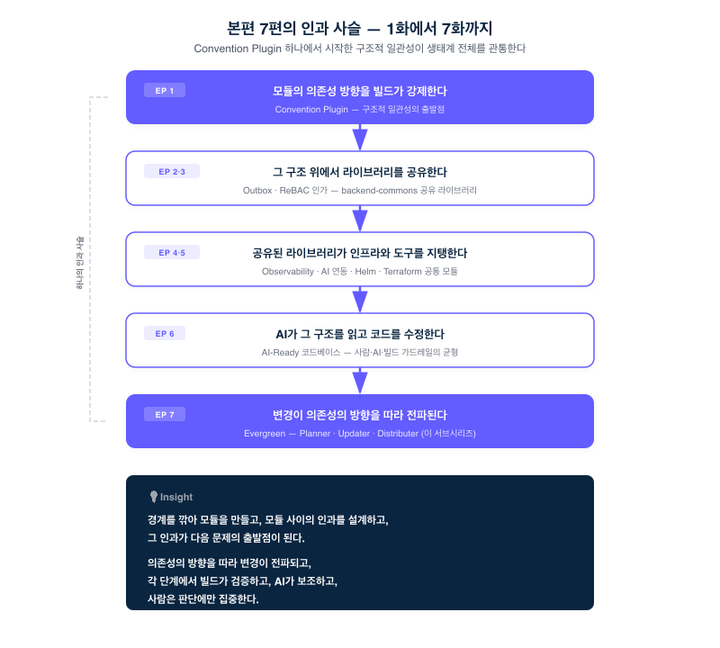
본편 각 편에서 Evergreen으로 이어지는 구체적 연결을 짚겠습니다.
본편 1화 -> Evergreen: Convention Plugin이 제공하는 구조적 일관성이 Planner, Updater, Distributer 모두의 전제입니다. 이것이 없으면 Evergreen 자체가 불가능합니다.
본편 2화 -> Evergreen: Outbox 라이브러리가 backend-commons에서 제공됩니다. 이 라이브러리를 업그레이드하면, 의존하는 모든 서비스 레포에 전파해야 합니다. Evergreen이 이 전파를 자동화합니다.
본편 3화 -> Evergreen: ReBAC 모델의 인가 라이브러리도 마찬가지입니다. 인가 정책이 변경되면, 관련 라이브러리가 업데이트되고, Evergreen이 전파합니다.
본편 4화 -> Evergreen: 멀티클라우드 Observability 설정, AI 연동 라이브러리 등 인프라 공통 모듈의 변경도 Evergreen으로 전파됩니다.
본편 5화 -> Evergreen: Helm chart, Terraform 모듈도 버전 관리되며, 개발 도구의 업데이트도 같은 전파 메커니즘을 공유합니다.
본편 6화 -> Evergreen: AI 에이전트가 빌드 에러를 분석하고 수정하는 능력이 Updater의 Claude 통합으로 직결됩니다. AI-Ready 코드베이스가 아니면, Claude가 코드를 수정하기 어렵습니다. 더 근본적으로, 본편 6화가 정립한 균형 — 사람에게만 의존하면 느려지고, AI에 전적으로 맡기면 질이 떨어지며, 그 사이를 빌드 가드레일이 잡는다 — 이 Evergreen에서 그대로 작동합니다. 결정론적 recipe가 속도를, Claude가 판단의 유연성을, 빌드와 테스트가 정확성을, 사람이 도메인 판단을 맡습니다. Evergreen은 본편 6화의 그 명제를 50개 레포 규모의 버전 전파에 적용한 결과입니다.
모든 레포가 같은 구조라서 가능한 것
지금까지의 다섯 편에서 반복적으로 등장하는 패턴이 있습니다. "모든 레포가 같은 구조"라는 전제가, 그 위에서 작동하는 자동화를 가능하게 한다는 것.
이것을 구조적 균질성(Structural Homogeneity)이라고 부를 수 있습니다. 각 레포가 개별적으로는 유연하게 도메인 로직을 구현하지만, 빌드 구조, 의존성 선언, CI 파이프라인, 퍼블리시 방식은 동일합니다.
구조적 균질성이 가능하게 하는 것:
1. recipe 하나 -> 50개 레포에 동일 적용
2. 파서 하나 -> 50개 레포의 의존 그래프 구축
3. CI 추적 로직 하나 -> 50개 레포의 상태 모니터링
4. 에스컬레이션 정책 하나 -> 50개 레포에 동일 적용
구조적 균질성이 없으면:
1. recipe 50개 -> 레포당 하나씩 (유지보수 불가)
2. 파서 50개 -> 레포마다 다른 형식 (유지보수 불가)
3. CI 추적 로직 50개 -> 레포마다 다른 파이프라인
4. 에스컬레이션 정책 50개 -> 레포마다 다른 기준Google, Spotify, Airbnb의 비슷한 시도
지금까지의 이야기가 한 조직만의 특수한 해법처럼 들렸을지 모릅니다. 하지만 Evergreen이 독특한 시도는 아닙니다. 대규모 코드베이스를 운영하는 조직들은 규모가 임계점을 넘는 순간 거의 예외 없이 같은 벽에 부딪히고, 놀랍도록 닮은 방식으로 그 벽을 넘습니다. 세부 도구는 다르지만, 그 밑에 깔린 원칙이 같다는 점을 보면 이게 우연한 선택이 아니라 문제의 구조가 강제하는 귀결임을 알 수 있습니다.
Google: 모노레포 + 대규모 변경 도구
Google은 모든 코드를 하나의 모노레포에 보관합니다. 의존성 변경이 필요하면, 내부 도구로 모노레포 전체에 걸쳐 변경을 적용합니다.
- Rosie: 대규모 코드 변경(Large-Scale Change)을 관리하는 내부 도구
- 강점: 모노레포라서 의존 그래프가 명시적. 변경 전파가 원자적(atomic)
- flex와의 차이: flex는 폴리레포. 레포 간 경계를 넘어야 하므로, Wave 기반 전파가 필요
Spotify: Backstage + 자동화 파이프라인
Spotify는 Backstage를 통해 서비스 카탈로그를 관리하고, 공통 라이브러리 업그레이드를 자동화합니다.
- Backstage: 서비스 메타데이터 관리, 의존 관계 시각화
- 강점: 개발자 포털과 통합된 의존성 관리
- flex와의 차이: flex는 빌드 시스템 수준의 자동화. Backstage보다 더 낮은 레이어에서 작동
Airbnb: 버전 전파 자동화
Airbnb는 내부 라이브러리의 버전 업그레이드를 자동화하는 시스템을 구축했습니다.
- 강점: PR 자동 생성, CI 상태 추적
- flex와의 차이: flex는 OpenRewrite를 통한 코드 변환까지 자동화. 단순 버전 변경을 넘어 API 마이그레이션까지 처리
공통점
| 요소 | Spotify | Airbnb | flex | |
|---|---|---|---|---|
| 의존 그래프 분석 | 모노레포 내 빌드 시스템 | Backstage 카탈로그 | 내부 메타데이터 | Planner (버전 관리 플러그인) |
| 코드 변환 | Rosie | 수동 + 자동 | 제한적 | Updater (OpenRewrite + Claude) |
| PR 전파 | 모노레포라 불필요 | 자동 PR | 자동 PR | Distributer (Wave 기반) |
| 구조적 전제 | 모노레포 강제 | Backstage 등록 강제 | 템플릿 기반 | Convention Plugin 강제 |
공통점은 명확합니다. 자동화의 전제는 일관성이라는 것. Google은 모노레포로 일관성을 강제하고, Spotify는 카탈로그 등록으로, flex는 Convention Plugin으로 일관성을 확보합니다. 방법은 다르지만, "일관된 구조 위에서만 전역 자동화가 가능하다"는 원칙은 같습니다. 흥미로운 건 이들이 서로의 해법을 베낀 게 아니라는 점입니다. 각자 자기 규모와 제약 속에서 독립적으로 도달한 결론이 같다면, 그건 취향이 아니라 문제가 강제하는 답입니다. 일관성을 어떻게 확보하느냐는 조직마다 다를 수 있어도, 일관성 없이 전역 자동화를 하려는 시도는 어디서도 성립하지 않습니다.
목표: 패치 1일, 마이너 1주, 메이저 2주
Evergreen의 정량적 목표를 다시 정리합니다.
| 변경 유형 | Before (수동) | After (Evergreen) | 에스컬레이션 비율 목표 |
|---|---|---|---|
| 긴급 보안 패치 | 1-2주 | 1일 이내 | < 3% |
| 패치 버전업 | 2-4주 | 1일 | < 5% |
| 마이너 버전업 | 4-8주 | 1주 | < 15% |
| 메이저 버전업 | 1-3개월 (또는 미룸) | 2주 | < 30% |
이 목표가 달성되면, "버전업을 미루는" 습관이 사라집니다. 미루지 않아도 되니까요. 1화에서 미루기가 위험했던 이유는 단순히 일이 쌓여서가 아니라, 쌓이는 동안 문제들이 서로 엉켜 난이도가 곱으로 올라가기 때문이었습니다. 비용이 충분히 낮아지면 이 악순환의 입구 자체가 닫힙니다 — 패치가 나오면 하루 안에 적용되고, 마이너가 나오면 일주일 안에 적용되니, 애초에 엉킬 만큼 쌓이지 않습니다. 기술 부채가 복리로 쌓이던 곡선이, 작은 변경을 자주 흘려보내는 평평한 선으로 바뀝니다.
보안 취약점에 대한 대응도 달라집니다. Log4Shell 같은 긴급 상황에서, "어떤 레포가 어떤 버전을 쓰고 있는지 파악하는 데 하루"가 아니라, "Planner가 즉시 영향 범위를 파악하고, Updater가 패치를 적용하고, Distributer가 PR을 전파"하는 구조. 파악에서 적용까지 하루 안에.
Evergreen은 끝이 아니라 시작이다
Evergreen이 완성되면 새로운 가능성이 열립니다.
전방위 업그레이드
Spring Boot만이 아닙니다. Kotlin, Gradle, 테스트 프레임워크, Observability SDK, 모든 공유 라이브러리의 업그레이드가 같은 파이프라인을 탑니다. 새로운 종류의 변경이 추가될 때, recipe만 작성하면 됩니다. 파이프라인 자체를 수정할 필요가 없습니다.
API 계약 진화
이건 단순한 효율 개선을 넘어, 설계의 자유도를 바꾸는 변화입니다. 라이브러리 API를 변경할 때, "하위 호환성을 깨면 안 된다"는 제약이 완화됩니다. recipe가 호출 코드를 자동으로 마이그레이션해 주니까요. 그동안 많은 나쁜 API가 "고치면 수십 개 레포가 깨지니까" 그대로 방치되어 왔습니다. 마이그레이션 비용이 변경을 가로막는 보이지 않는 세금이었던 셈입니다. 그 세금이 사라지면, 라이브러리 작성자는 호환성 걱정 대신 더 나은 API를 설계하는 데 집중하고, 마이그레이션 비용은 Evergreen이 처리합니다.
보안 거버넌스
의존성의 취약점을 스캔하고, 패치가 가능한 경우 자동으로 적용하는 보안 파이프라인. Evergreen과 취약점 스캐너를 연결하면, "취약점 발견에서 전사 패치 완료까지"가 자동화됩니다.
마지막 편의 끝에서
본편 1화에서 시작한 이야기가, 본편 7편과 이 심화 편의 마지막까지 하나의 인과 사슬로 이어졌습니다.
모듈의 의존성 방향을 빌드가 강제한다 (본편 1화)
-> 그 구조 위에서 라이브러리를 공유한다 (본편 2화, 3화)
-> 공유된 라이브러리가 인프라와 도구를 지탱한다 (본편 4화, 5화)
-> AI가 그 구조를 읽고 코드를 수정한다 (본편 6화)
-> 변경이 의존성의 방향을 따라 전파된다 (본편 7화, 그리고 이 심화 편)Convention Plugin 하나에서 시작한 구조적 일관성이, 레포의 경계를 넘어 생태계 전체를 관통하는 자동화 파이프라인이 된 것. 의존성의 방향을 따라 변경이 전파되고, 그 전파의 각 단계에서 빌드가 검증하고, AI가 보조하고, 사람은 판단에만 집중합니다.
경계를 깎아서 모듈을 만들고, 그 모듈 사이의 인과를 설계하고, 그 인과가 다음 문제의 출발점이 되는 경험. 이 경험이 반복될수록, 다음 문제가 와도 처음부터 시작하지 않습니다.
Evergreen은 그 반복의 현재 지점이고, 다음 고리는 아직 이어지지 않았습니다.
🚀플렉스팀 채용페이지 바로가기
☕flex Private Talk 신청하기